
A few months back I authored a post detailling the process of data replication from an ECC or S4 system into Google Big Query through the utilization of SAP Data Intelligence. In this prior post, I used a data pipeline for replication, specifically chosen to accommodate the requirements of Google Big Query as a target (it would have been the same for a Snowflake target). But for other targets, I could have used a feature known as Replication flow.
As you are aware, on the 8th of March, SAP made a significant announcement concerning the release of SAP Datasphere. This innovative evolution of SAP Data Warehouse Cloud incorporates several key attributes from SAP Data Intelligence, including Replication Flows. Currently, this feature facilitates data replication within SAP Datasphere itself, SAP HANA Cloud, SAP HANA Datalake Files, or SAP HANA (On Prem). Notably, the roadmap for Q4 2023 includes the expansion of target options to encompass Google Big Query, Google Cloud Storage, Amazon S3 and Microsoft Azure Data Lake Storage Gen2.
Quickly, customer inquiries came in, centered around the methodology of data replication utilizing the capabilities of SAP Datasphere. For an S/4HANA system, achieving this task becomes straightforward through the use of CDS ( Core Data Services). The core purpose of SAP Datasphere is to provide a Business Data layer for our customers, for them not to have to replicate table to table and go thru the laborious and error-prone process of building models but rather give them out of the box directly usable data. But still, among these questions, one particular focus was the replication of data from an SAP ECC source, more precisely, a table-to-table replication. Although I would strongly not advise to replicate table to table in a datalake and have the modelling done there, it is still an architecture model that we see. Maybe not for many years, as more and more customers will move to S/4HANA but still, it is a valid question.
For these customers, here is a blog explaining how to perform this table to table replication from an ECC system with SAP Datasphere using Replication Flows.
Before starting, I would like to thank Olivier SCHMITT for providing me with the SAP ECC system, along with the DMIS Addon and also for doing the installation of the SAP Cloud Connector, SAP Analytics Cloud Agent and SAP Java Connector on this box. I would like also to thank Massinissa BOUZIT for his support thoughout the whole process and especially with the SLT configuration and for partitioning the table MARA for me (As you’ll see for big tables, this is a must).
Here is the video :
So first you will have to log in your SAP Datasphere system and go to “System”, “Administration” and choose “Data Source Configuration”.
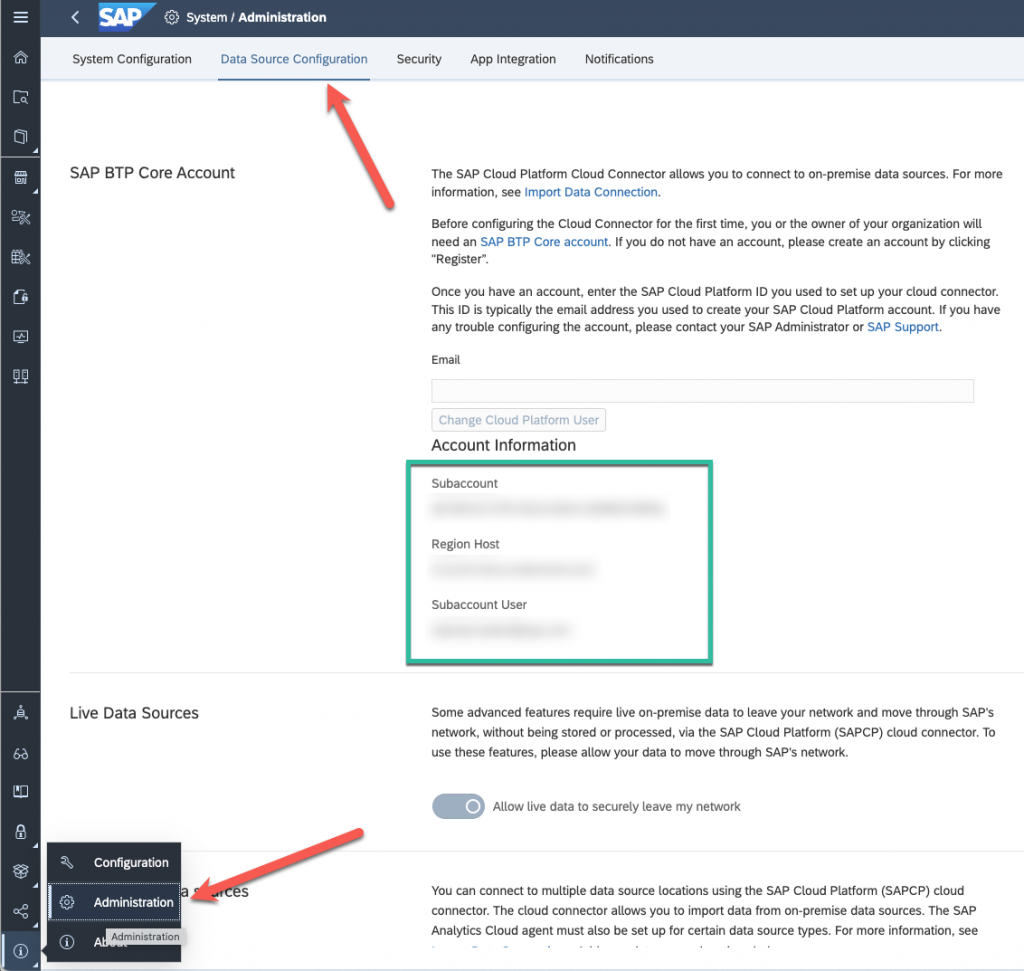
Here you will find several information, Subaccount, Region Host and Subaccount User (you will also need the subaccount user password)
After that you will have to install in your On Prem architecture the SAP Cloud connector, you will also need a SAP Analytics Cloud Agent, and the SAP Java Connector. I won’t go through this process as you can find documentation about this.
You also will need an SLT system or to install the DMIS Addon on your ECC system. In my case, I have the DMIS Addon on my ECC box, so I’ll talk about them in the same way, I hope it will not be too confusing.
So back to the process, log into your installed SAP Cloud Connector.
Add your SAP Datasphere Subaccount, using all the information we got on the SAP Datasphere system and give it a specific Location ID, make note of this, you will need afterwards.
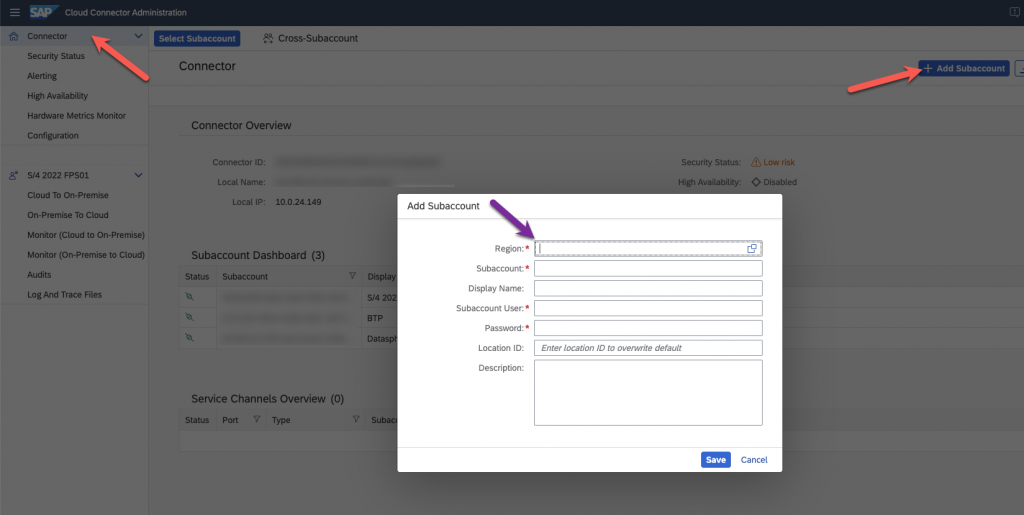
Now go to configure the Cloud to On-Premise for the Subaccount that you just created, for that click on Cloud to On-Premise, and select subaccount.
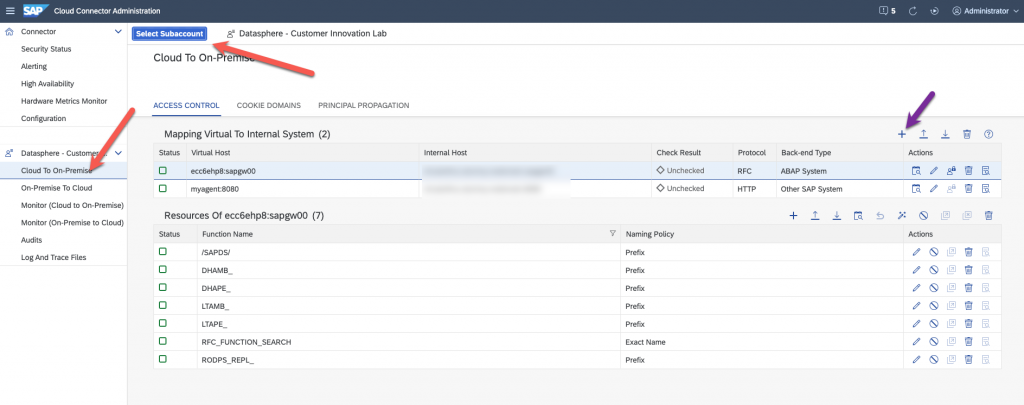
Add two Virtual mapping to internal systems. One for your SLT or DMIS addon, and one for the SAP Cloud Connector Agent. In my case, the DMIS Addon is on my SAP ECC system, that’s why I called it ecc6ehp8. You have then to enter the following ressources for the SAP ECC system, as explained in the help.
For the SAP Analytics Cloud agent, you will also have to enter a ressource.
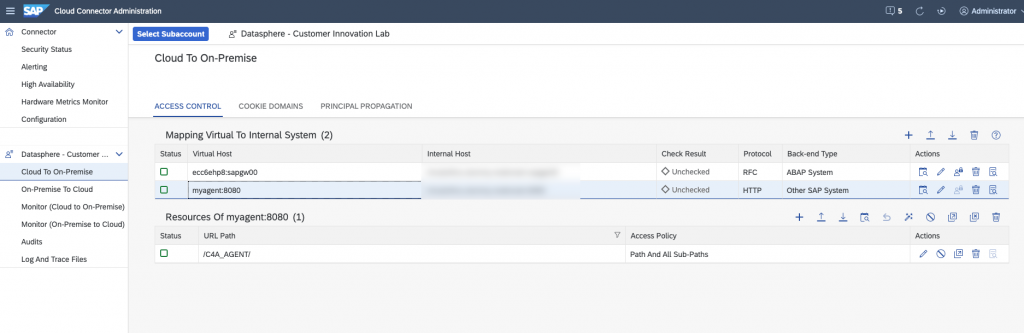
All the setup on the SAP Cloud Connector is done, we can go back to SAP Datasphere.
Here we are going to configure the location we created in the SAP Cloud Connector. Go back to system, administration, data source configuration and at the bottom, add a new location :
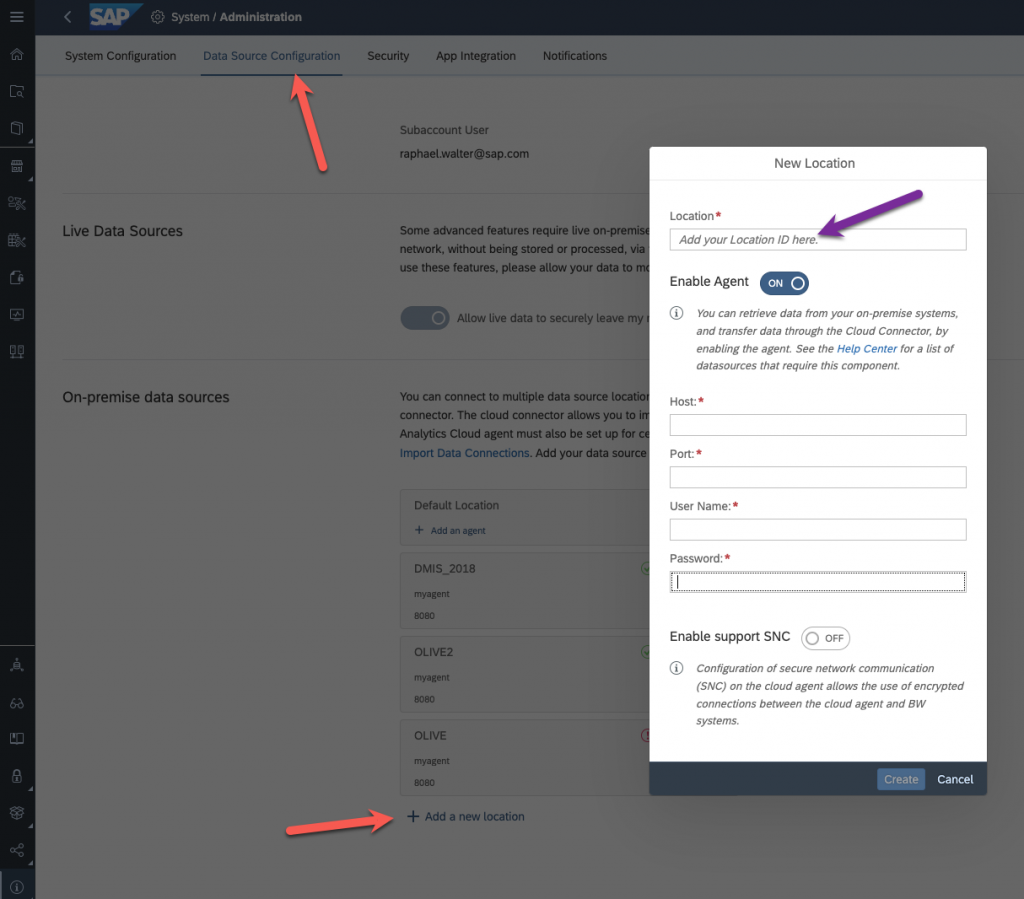
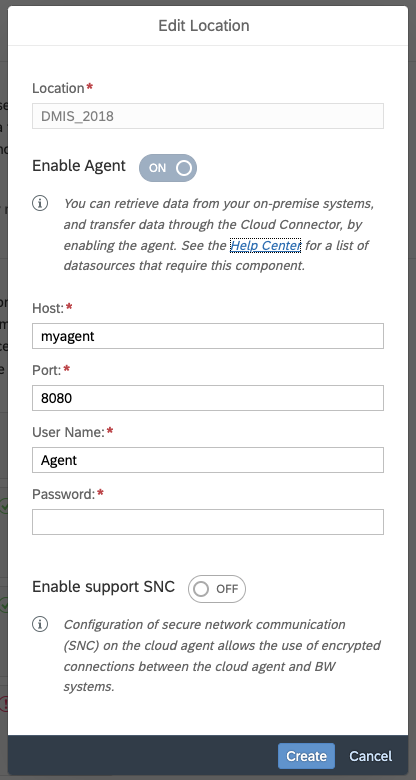
Use the same location ID as in the SAP Cloud Connector, for the host, the one of your SAP Analytics Cloud Agent, with user and password. By default, this is Agent/Agent.
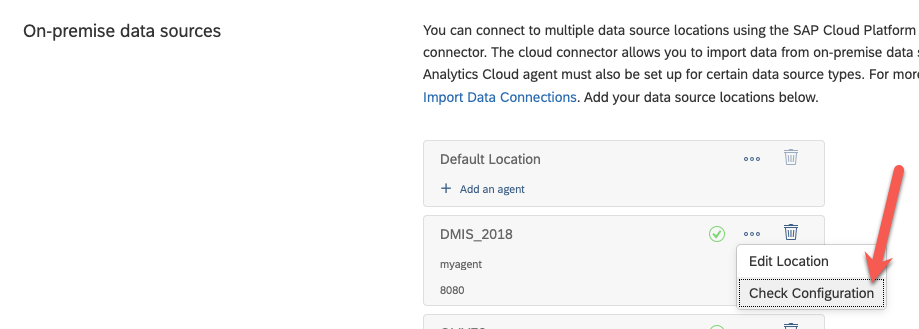
Check that everything is working
Now we can create the connection to our ECC system (actually to the SLT system)
Use all the information given in the SAP Cloud Connector, location ID, the virtual name you used for your mapping, etc… of course, don’t forget to configure the SAP Cloud connector! 🙂
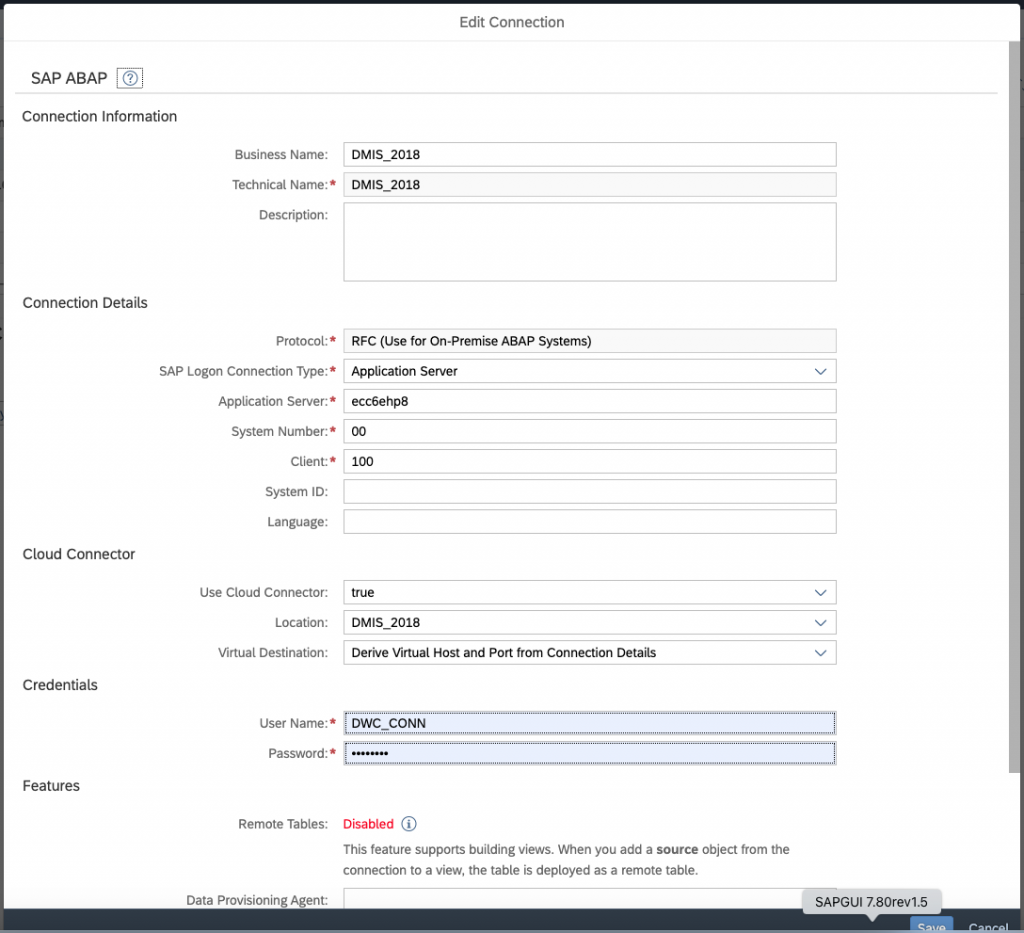
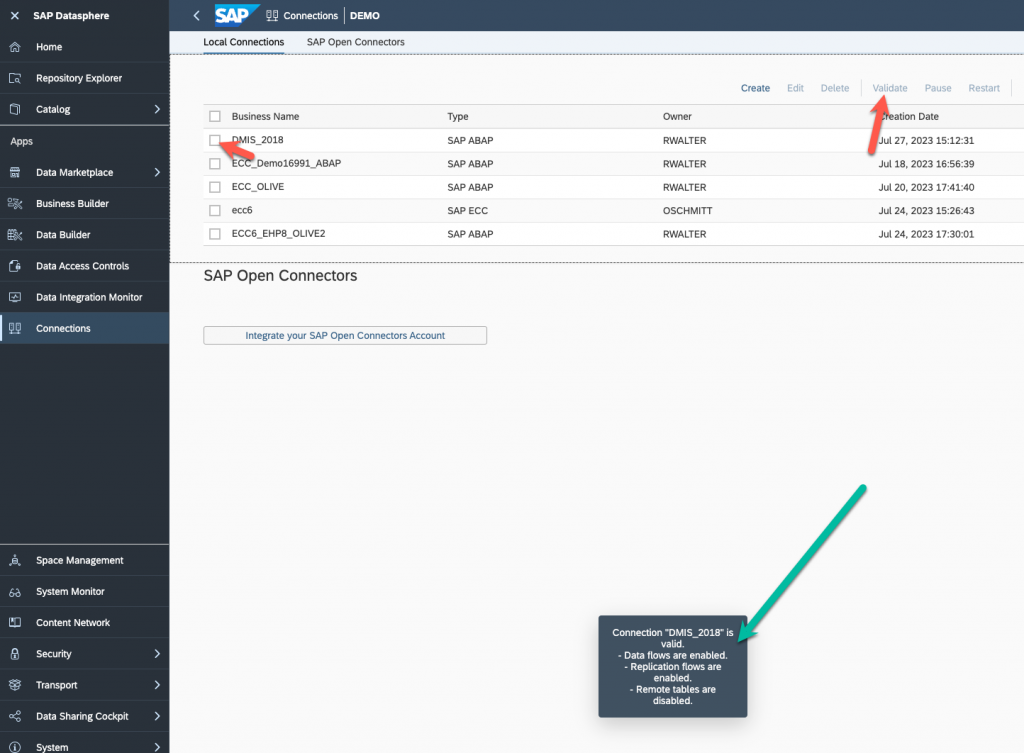
Verify your connection and validate that the Replication flow are configured correctly.
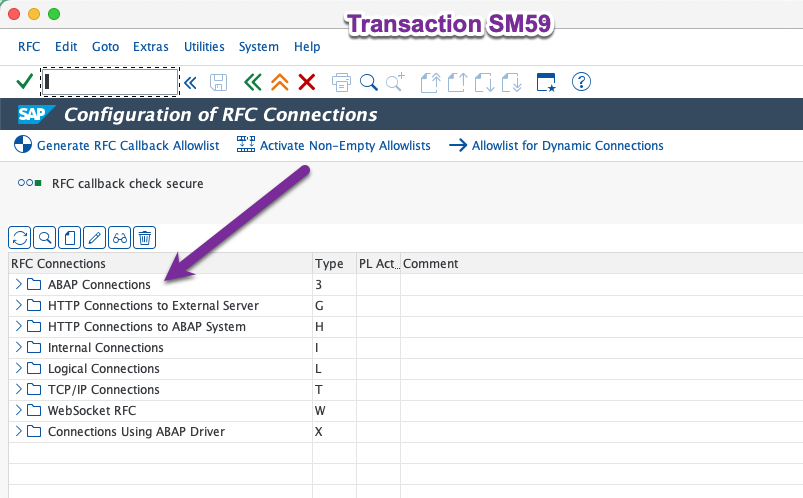
Now we can go to configure the SLT system, launch transaction SM59 :
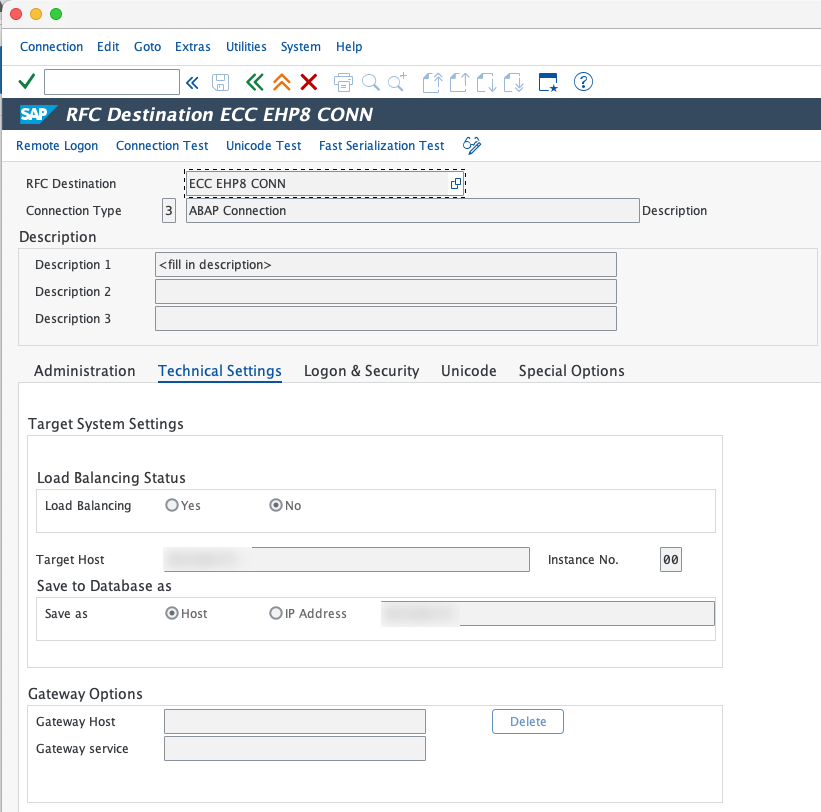
Add a new ABAP Connection to your SAP ECC system :
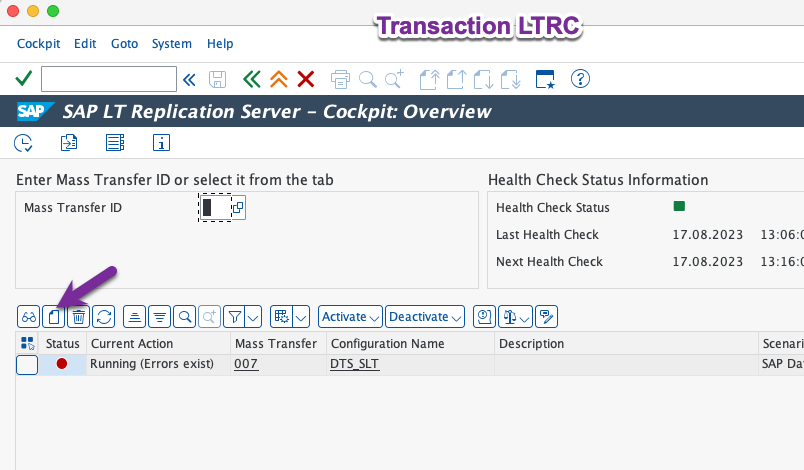
Now go to transaction LTRC, the SAP Landscape Transformation Replication Server Cockpit and create a new configuration.
Give it a name and click next.
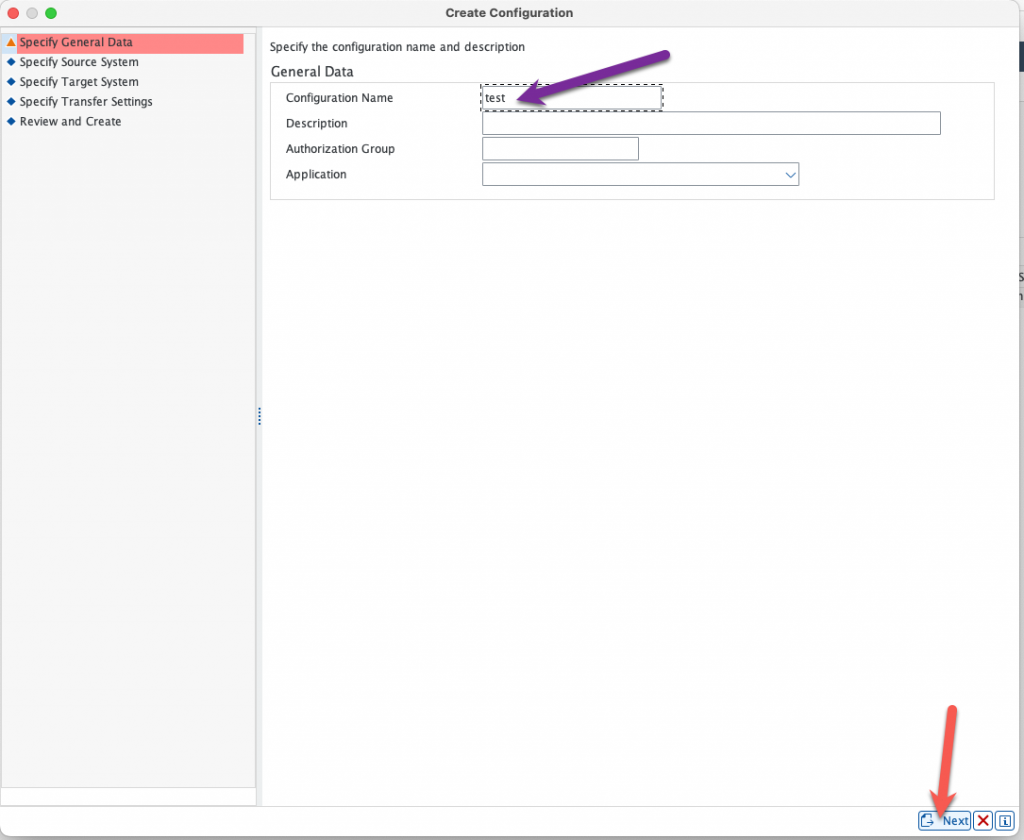
Select the RFC connection that you just created in transaction SM59 to your SAP ECC system :
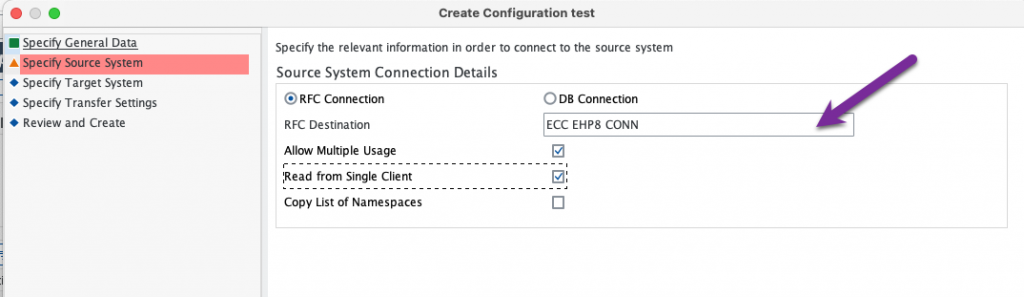
For the target system, choose “Other” and “SAP Data intelligence (Replication Management Service)”. As explained in the introduction, this is a feature coming from SAP Data Intelligence that was implemented in SAP Datasphere.
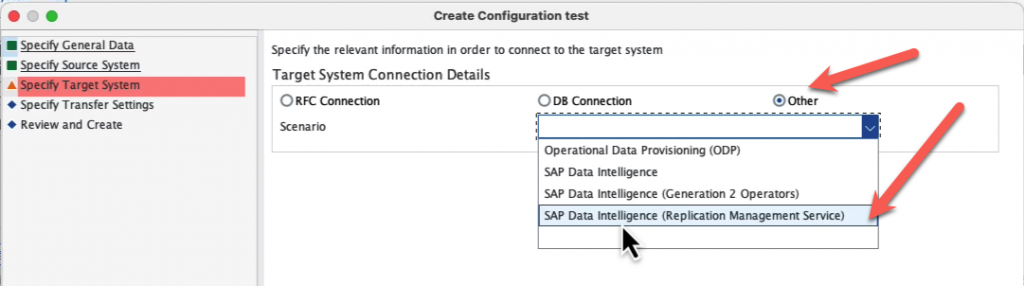
Specify if you want real time or not, please note that currently there is a limitation of one hour even with Real Time turned on for replication.
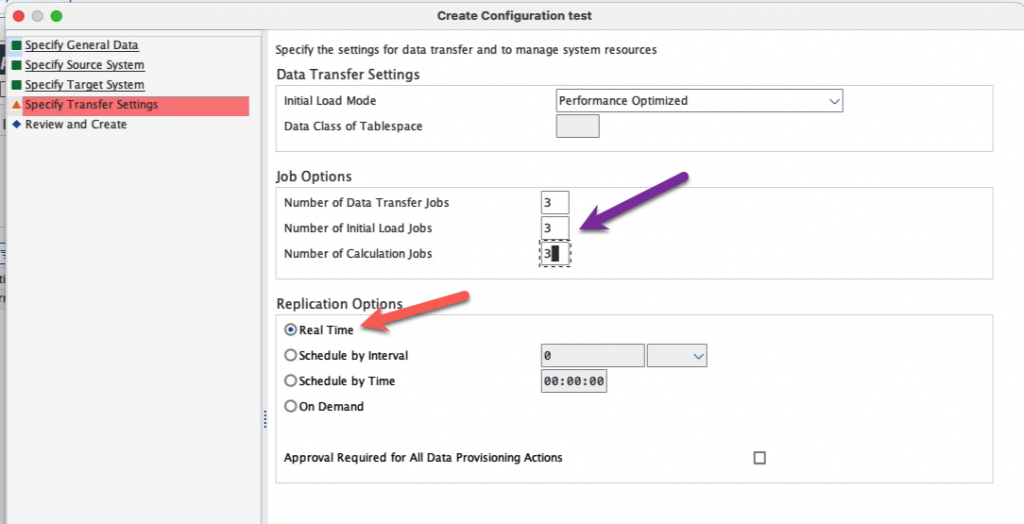
Finish and make note of the mass transfer ID of your configuration. We will not be adding tables here as this will be done on the SAP Datasphere side. Note also that you can see “NONE” as a target, although we specified SAP Data Intelligence Replication Management Service, this is normal.
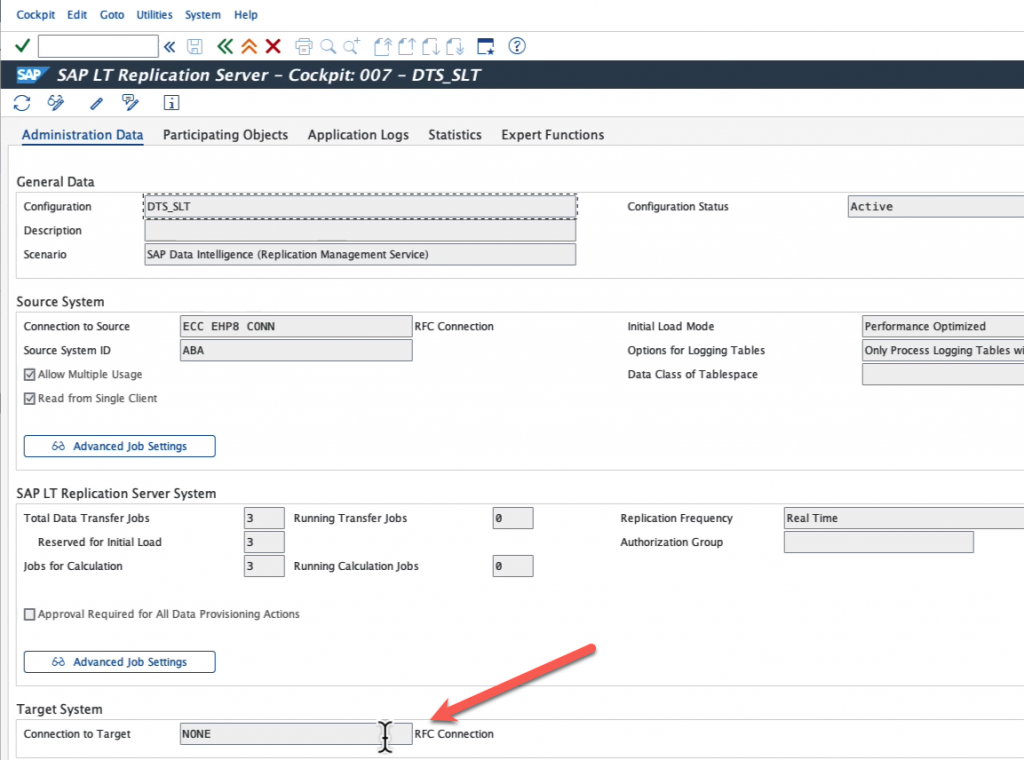
All the configuration steps are finished now, we can start replicating our data. Please note that for big tables, like MARA in this example, you will have also to partition your table to avoid getting an error message and having the replication flow to fail. I will not go into the details of partitioning your tables. For small tables, this will not be an issue.
Back to SAP Datasphere, go to Data Builder and create a new Replication flow :
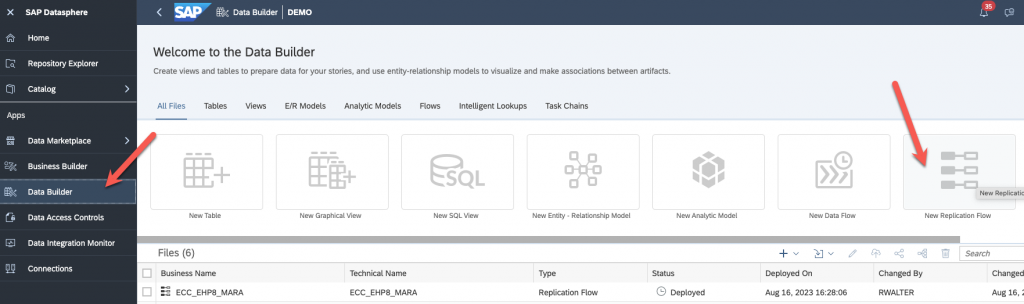
Select your source :
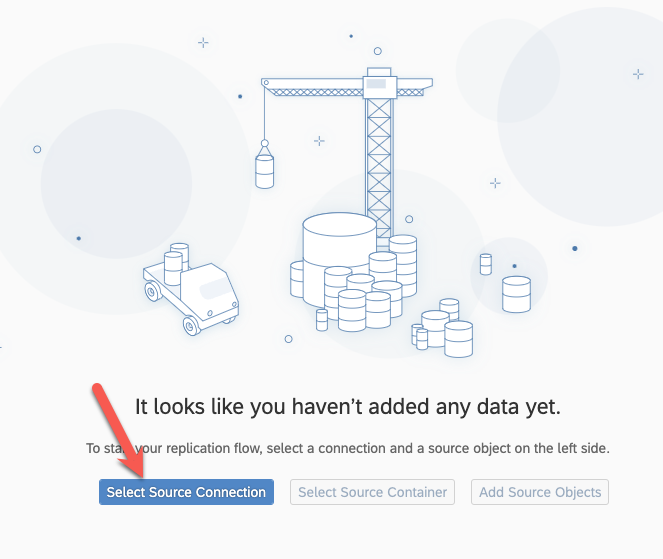
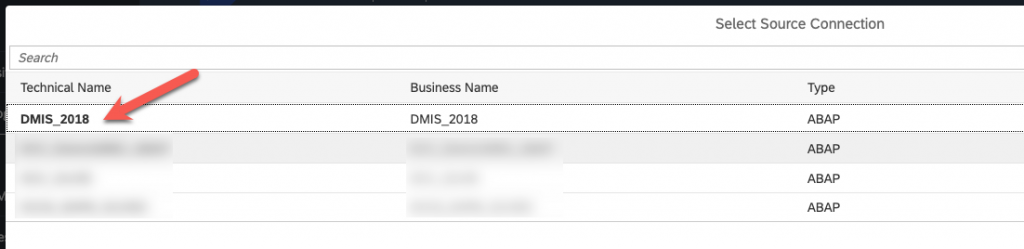
Select the connection you created previously :
Select the source container :
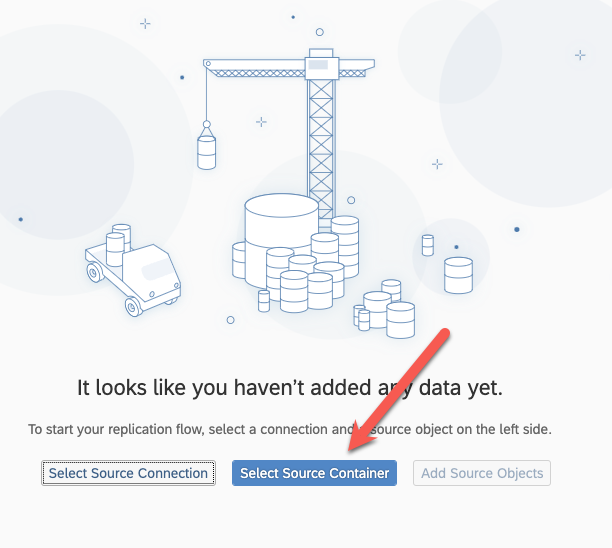
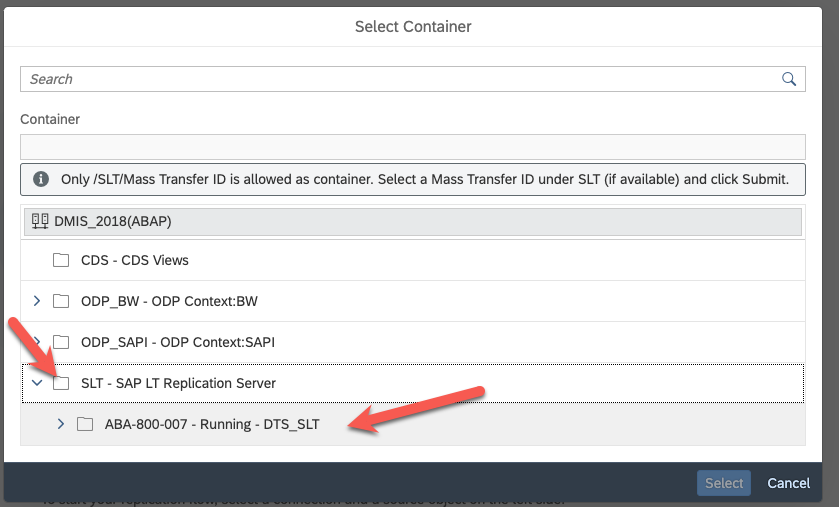
Select SLT as a source container and then the mass transfer ID of your configuration on the SLT system you previously created :
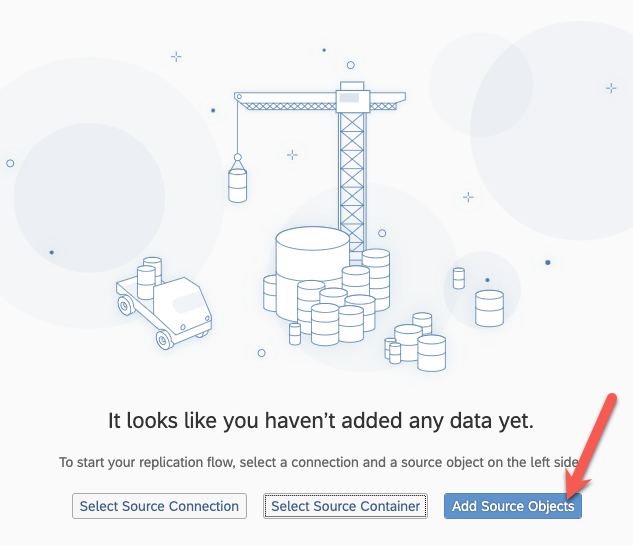
Add the source objects :
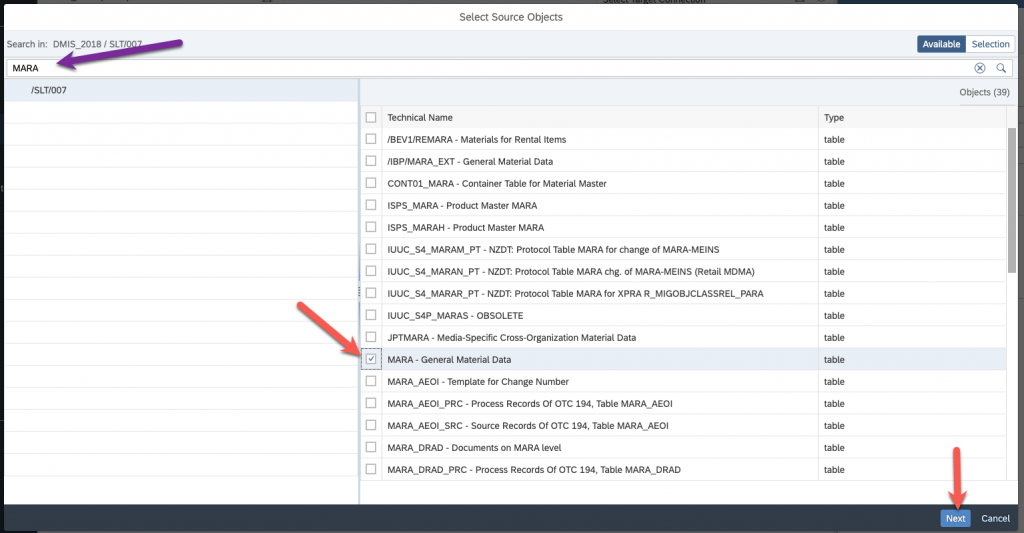
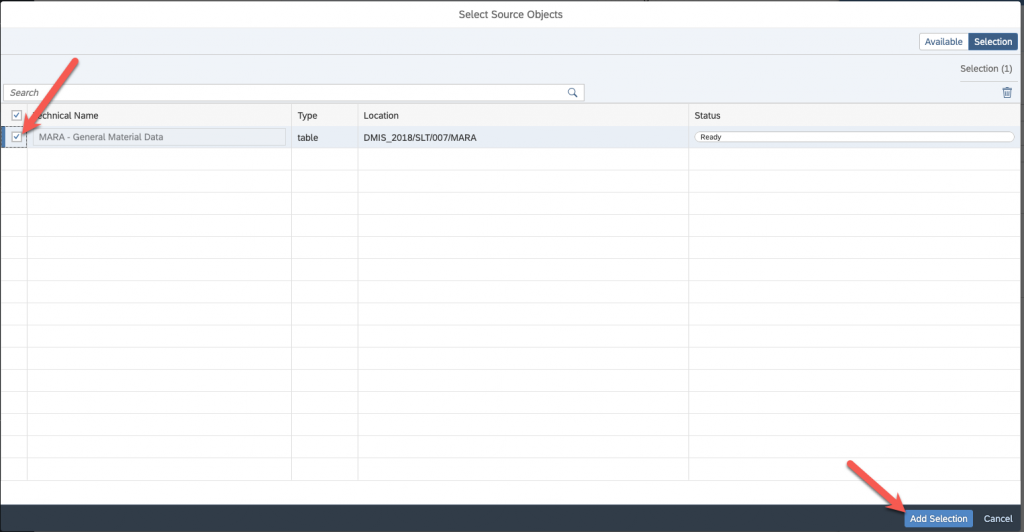
Search for the tables you wish to replicate, select them and add them :
Select again on the next screen and add the selection :
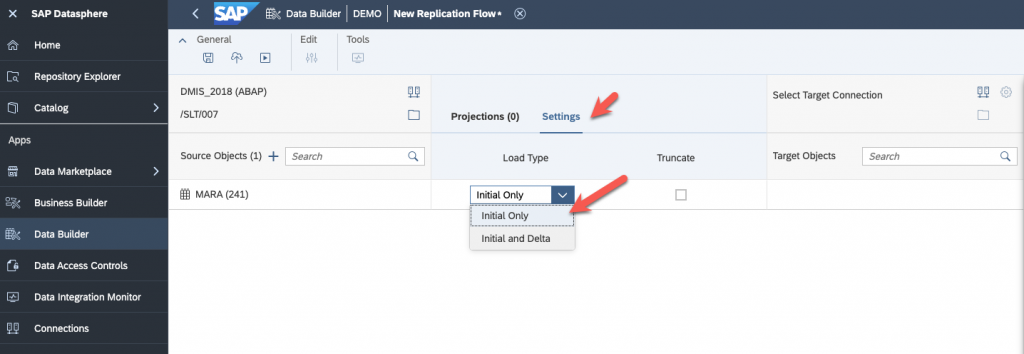
Specify the behavior of your replication flow (Initial Load, Deta):
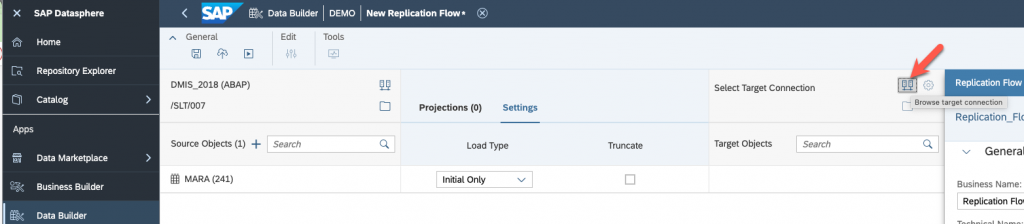
And select your target, in my case, SAP Datasphere itself.

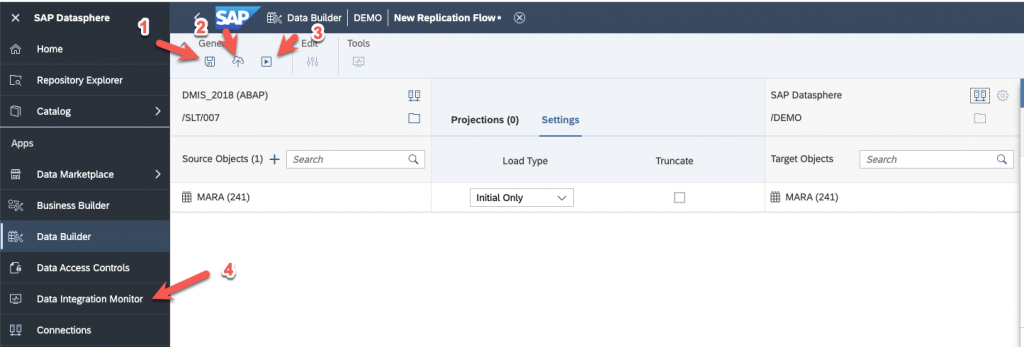
Now, save, deploy and run! You can go to the Data Integration Monitor to see if everything is going smoothly.
Go to Flow monitor and select your replication flow :
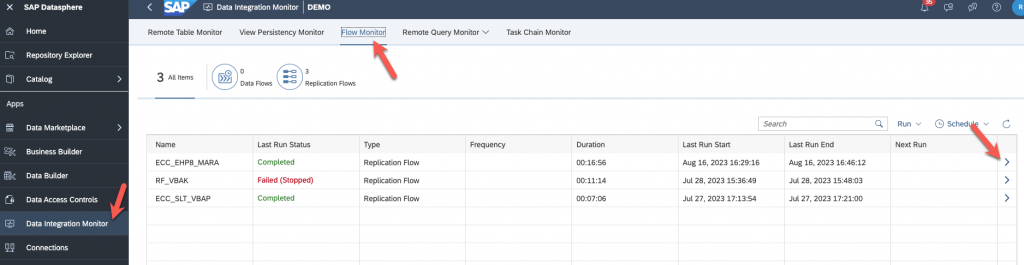
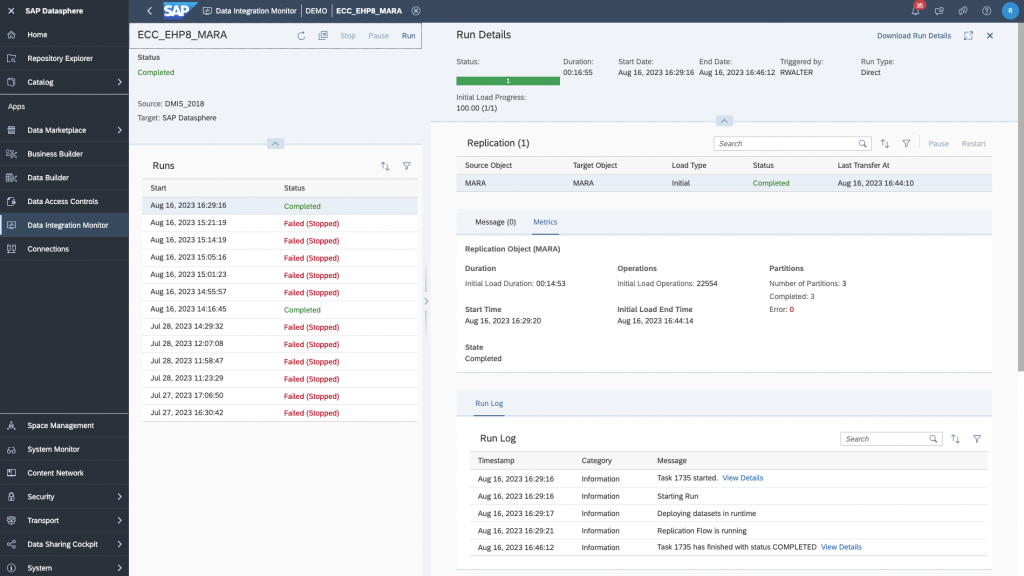
As I said, the many errors you see below are because I didn’t partition my MARA table which was too big. When I did, I all worked.
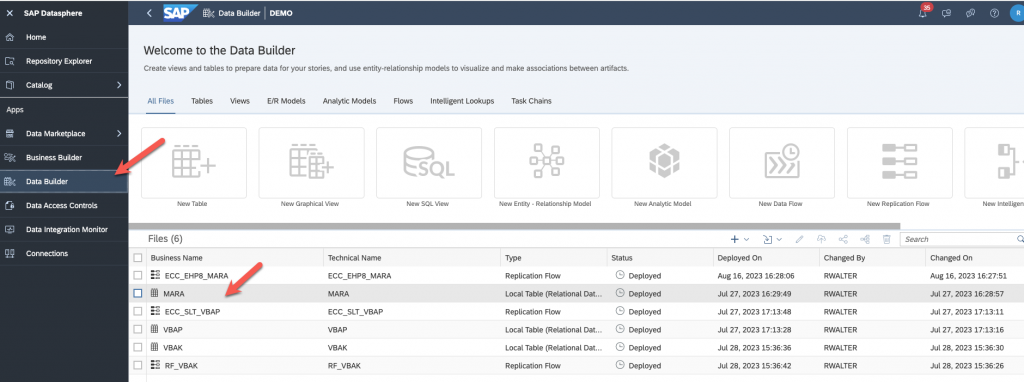
Go back to Data Builder and verify that the data was loaded correctly.
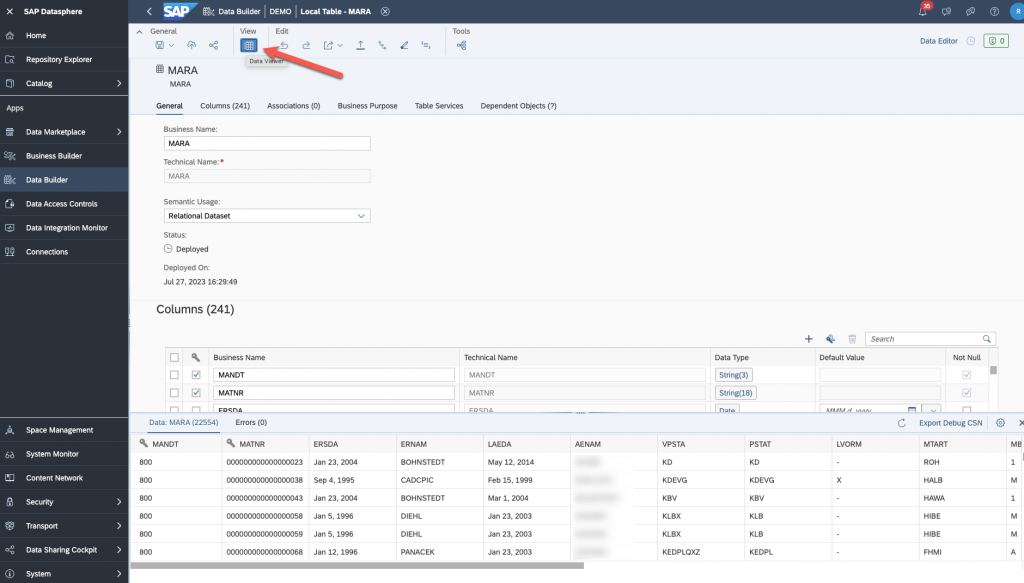
Click to preview you data and you should be all set!
I hope that this was useful for you. Don’t hesitate to leave a comment if you have a question.
Once again, I would like to thank Olivier SCHMITT for providing me with the SAP ECC system, along with the DMIS Addon and also for doing the installation of the SAP Cloud Connector, SAP Analytics Cloud Agent and SAP Java Connector on this box. I would like also to thank Massinissa BOUZIT for his support thoughout the whole process and especially with the SLT configuration and for partitioning the table MARA for me.