
Hello everyone,
Again another request from one of my customer, actually from several of my customers. How can you extract data from an ECC system or an S/4HANA system into Google Big Query with delta load? As you’ll see, this is very simple and straightforward using SAP Data Intelligence, you can perform Intial load, delta loads or replication(Intial Load and Delta loads). For one customer, the target was actuallly Google Cloud Storage, in this case it is even easier and you can rely on the SAP Data Intelligence RMS feature and directly connect your source to the target with replication.
In any case, enough talking, look at the following video and I will demonstrate how you can quickly this set up. Of course, you will need acces to an ECC or S/4HANA system with SLT or the DMIS addon installed and a Google Cloud account for Google Big Query and Google Cloud Storage(needed for staging the data). Please note that I will not go in the details of the configuration of the SLT. I’d like to take the time to give credit to Abdelmajid Bekhti, he was the one who showed me how to do this and provided me with all his systems and gave me access. I wouldn’t be able to show you anything without his help and knowledge.
Ok, now let’s get started! 🙂
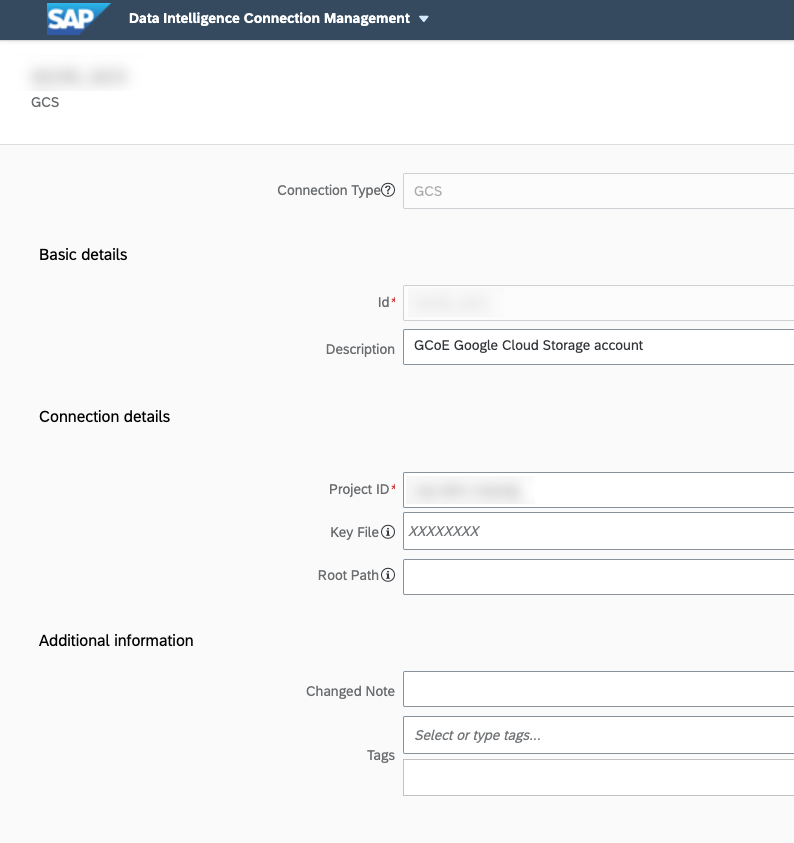
First you need to configure your connections to your systems in SAP Data intelligence. We need to configure the SLT, ECC (or S4/HANA), Google Cloud Storage and Google Big query connections. For that click on the connections tab.
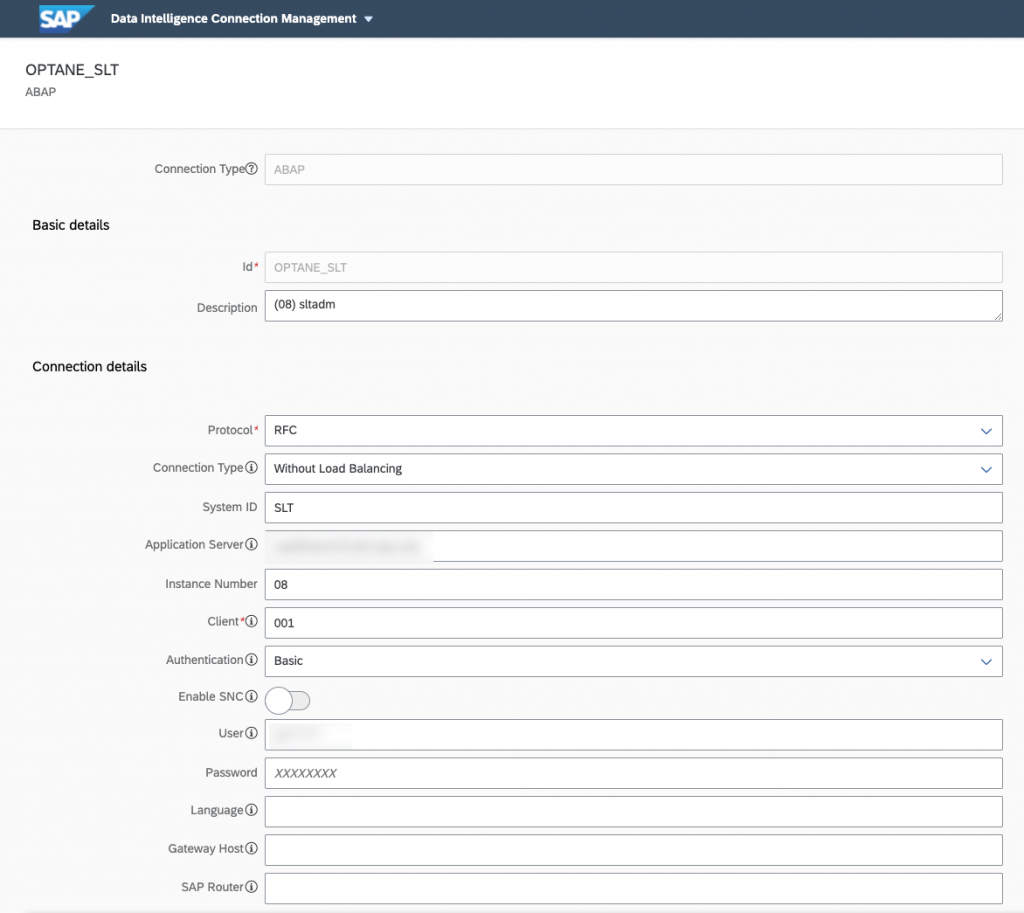
As you can see here, we’re using the SAP Cloud Connector to connect to our On Premise SLT system.
Then let’s have a look at our connection to Google Big Query.
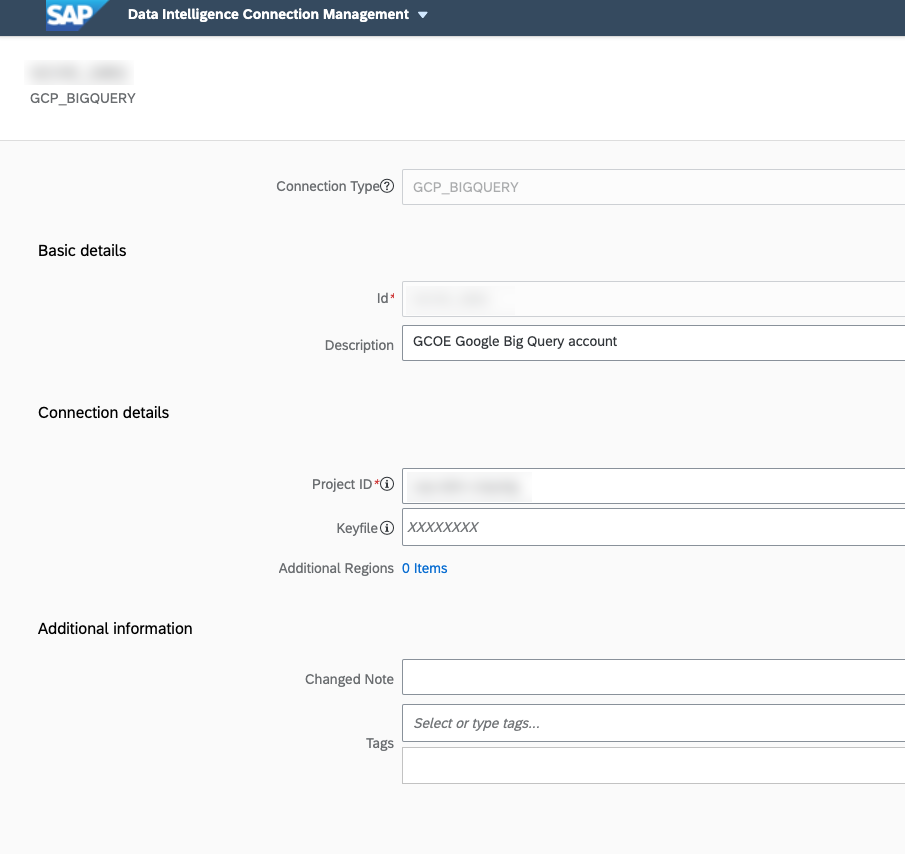
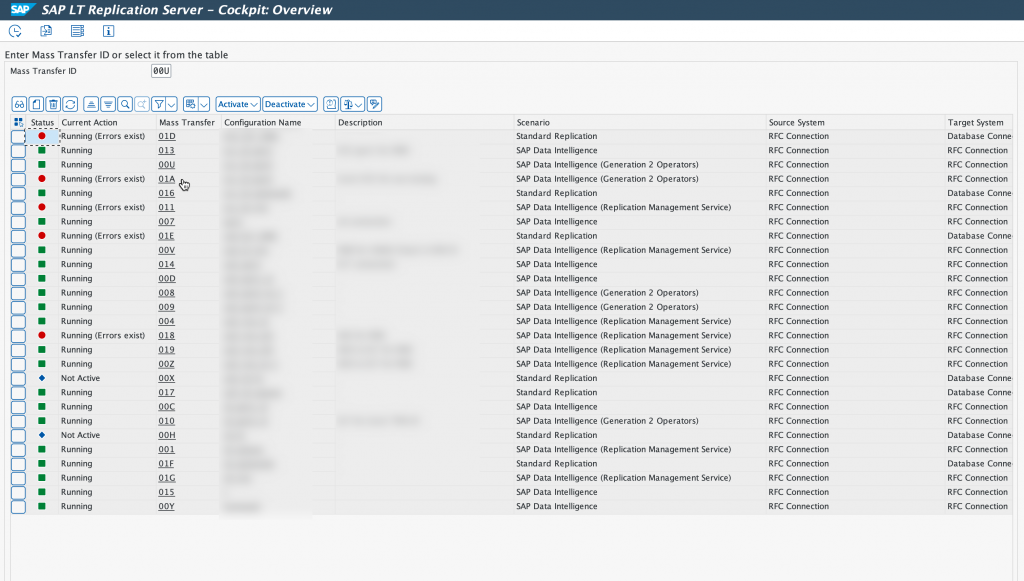
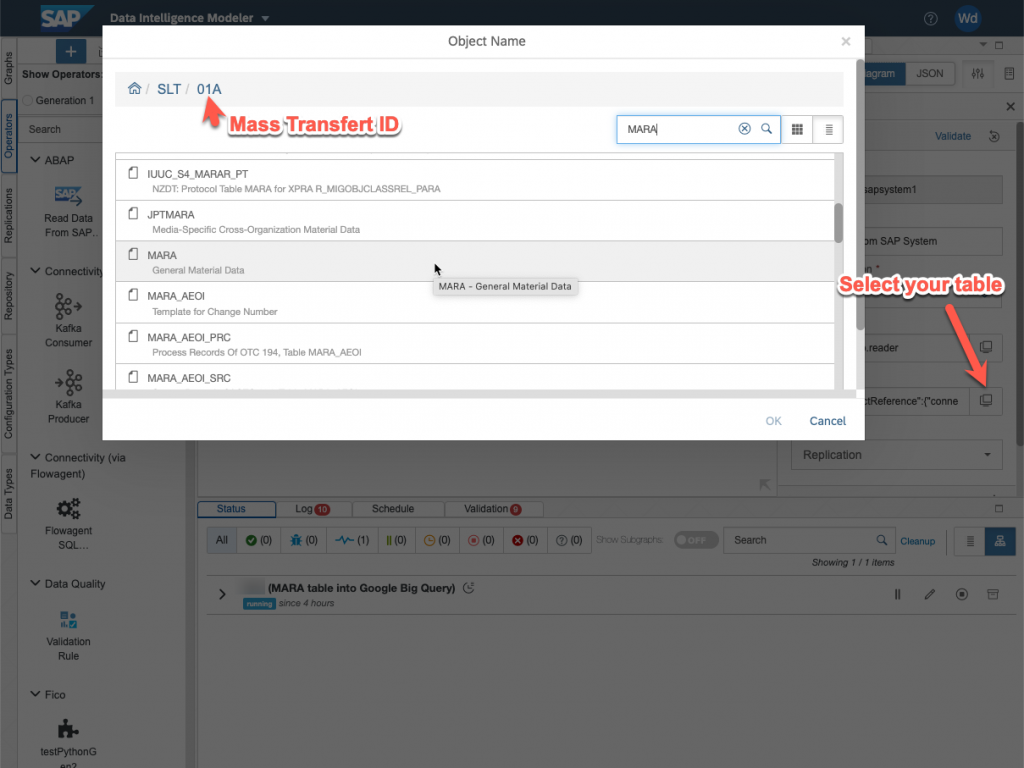
We are going to have a look at the Mass Transfer ID 01A, as you can see this is a Generation 2 operators, RFC connection with SAP Data Intelligence.
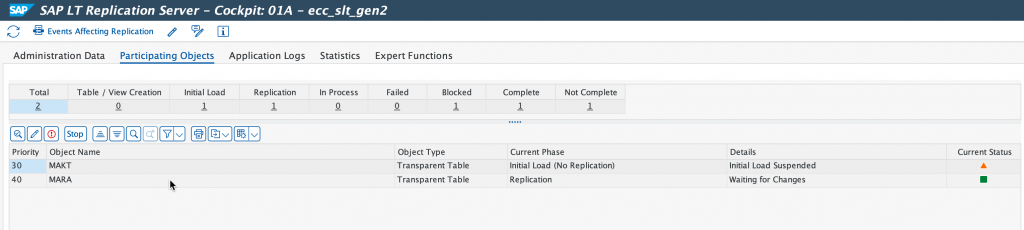
As you can see we are replicating table MARA from our ECC system. And this is done in real time.
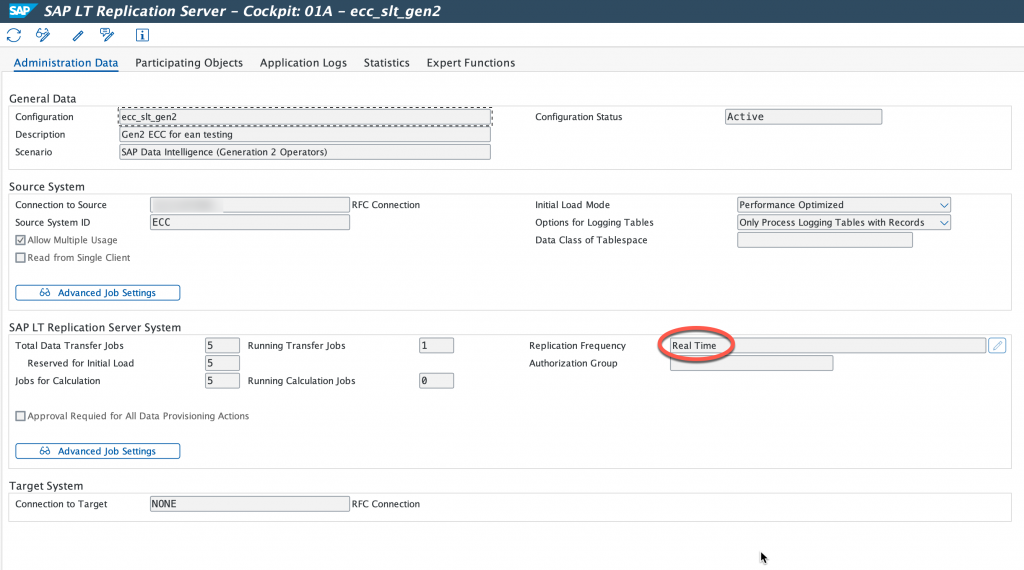
Once again, I will not through the details of setting up SLT. But everything is done correctly and we can proceed. As you saw, in this demo, we are going to replicate table MARA. The next step is to create a target table in Google Big query, for this you need to extract the data structure of the table you wish to replicate from your ERP system. You can refer to this blog to see how to extract this table structure. Downloading Data Dictionary Structure into local file
In my case, I used DD03VT in SE11 to extract table MARA. I didn’t make exactly the same data structure with the exact types, and just used strings and had to modify some of the names as I could not create fields with ‘/’ in their names in Google Big Query tables.
Now let’s look at the pipeline. As you will see, it is incredibly simple… We are using Generation 2 operators, with Generation 1, the data pipeline would be more complex. Just to explain, SAP Data Intelligence Generation 2 operators are based on Python 3.9 whereas Generation 1 operators using Python 3.6.
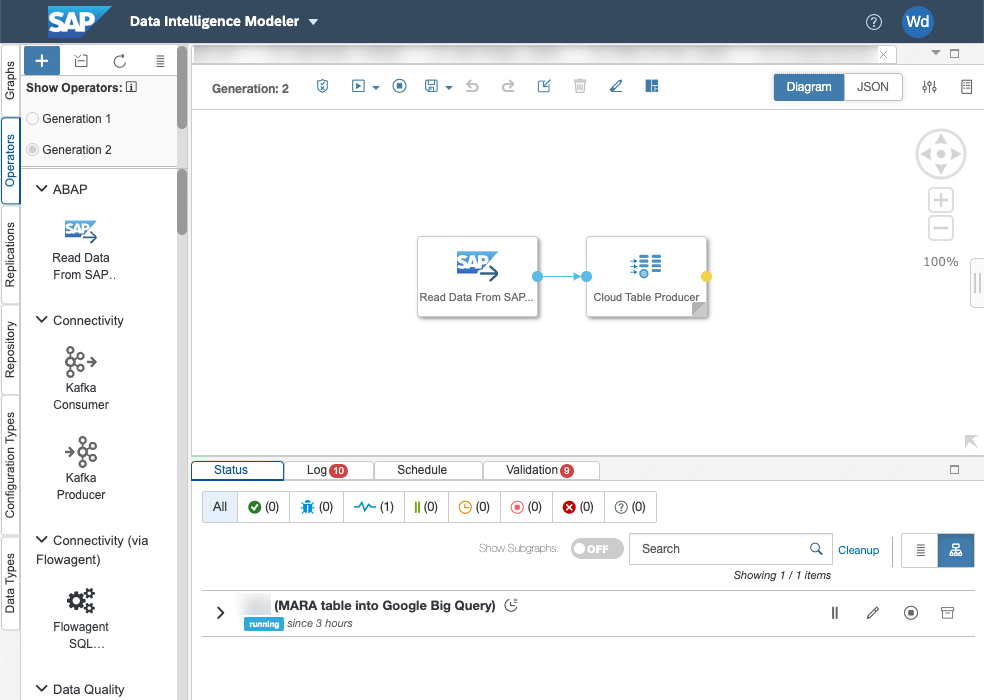
We are using the “Read Data from SAP System” operator to connect to SLT and the Cloud Table Producer operator to connect to Google Big Query (this operator can connect to Google Big Query or Snowflake).
Let’s look at the configuration of our Read Data from SAP System operator.
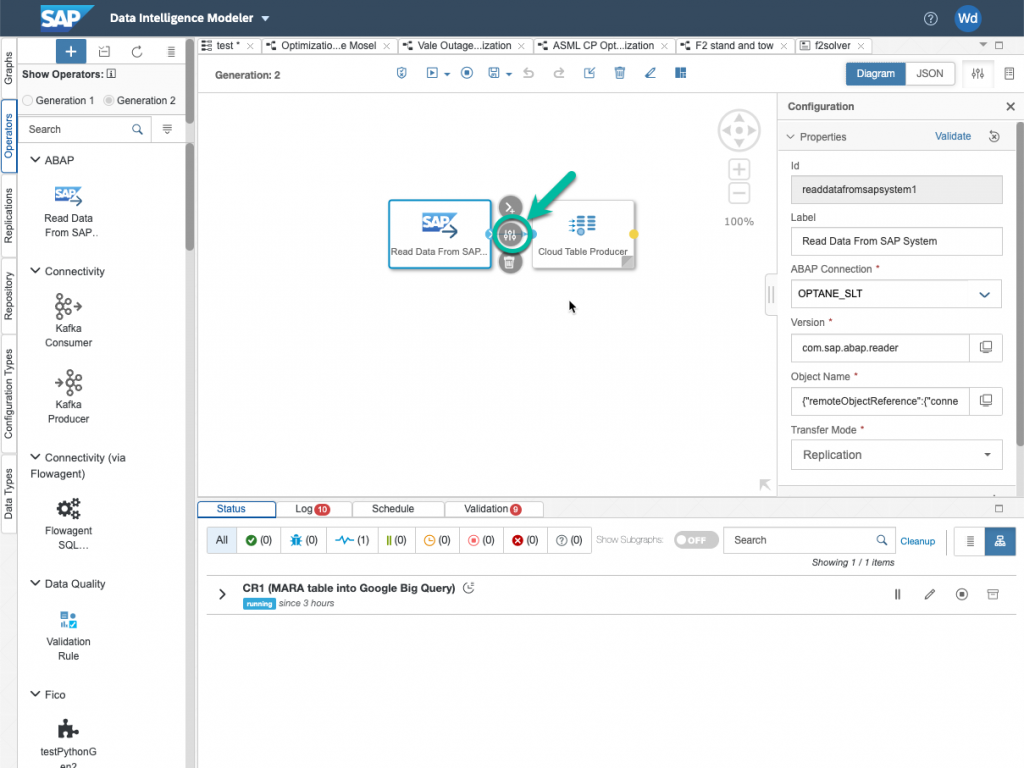
Choose the correct connection, in our case the SLT connection shown earlier. And then click on object Name to select the Mass Transfer ID and table you want to replicate.
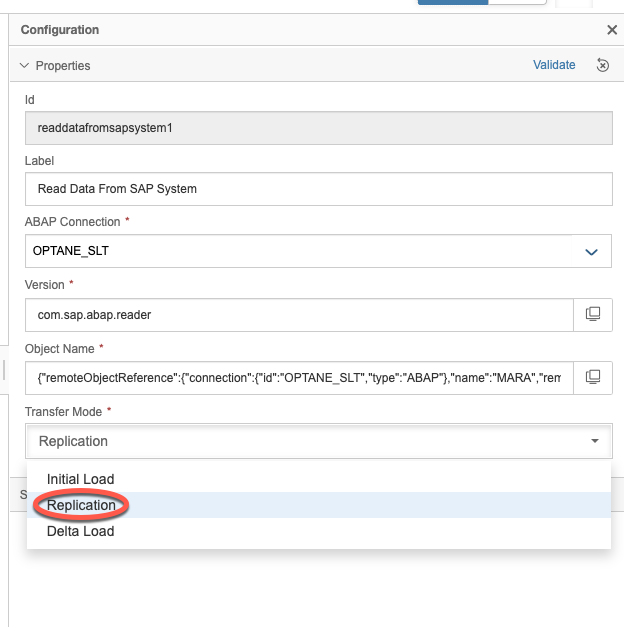
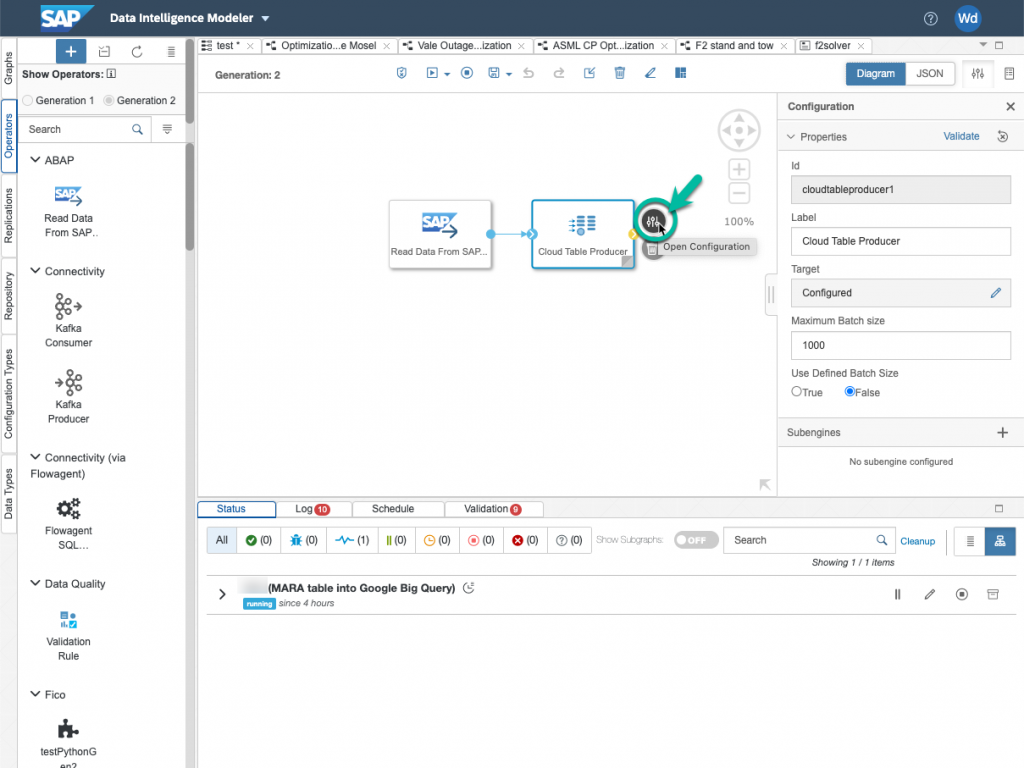
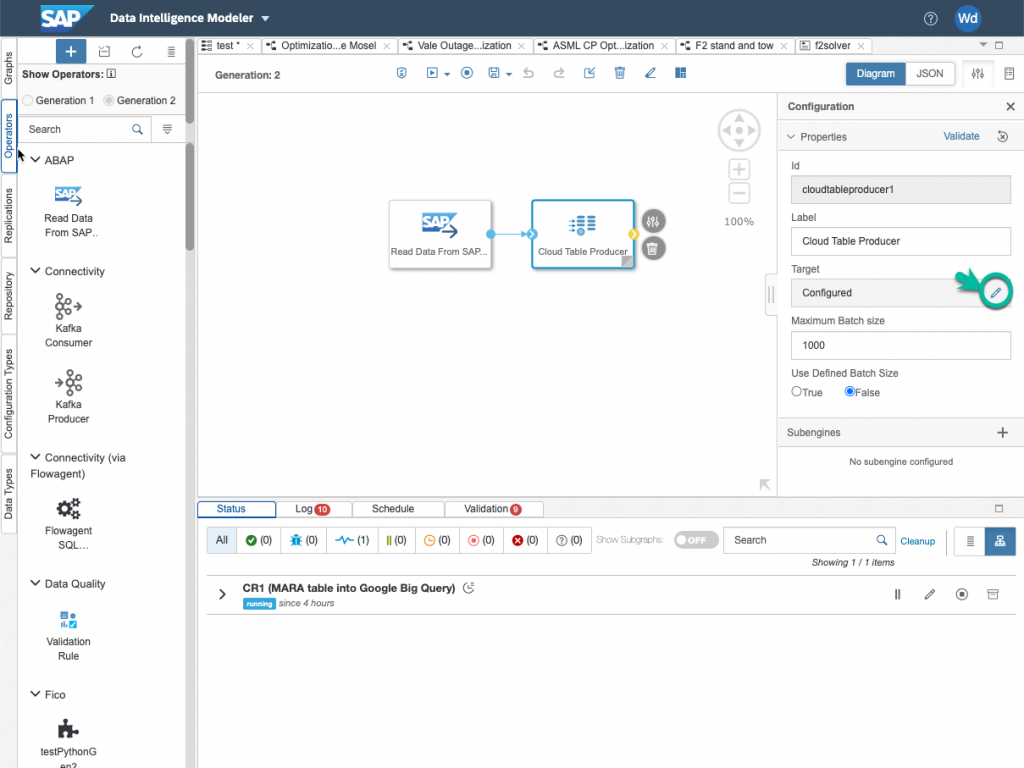
For the staging connection ID, choose your Google Cloud Storage connection. For the staging Path, simply choose where the staging table will be created.
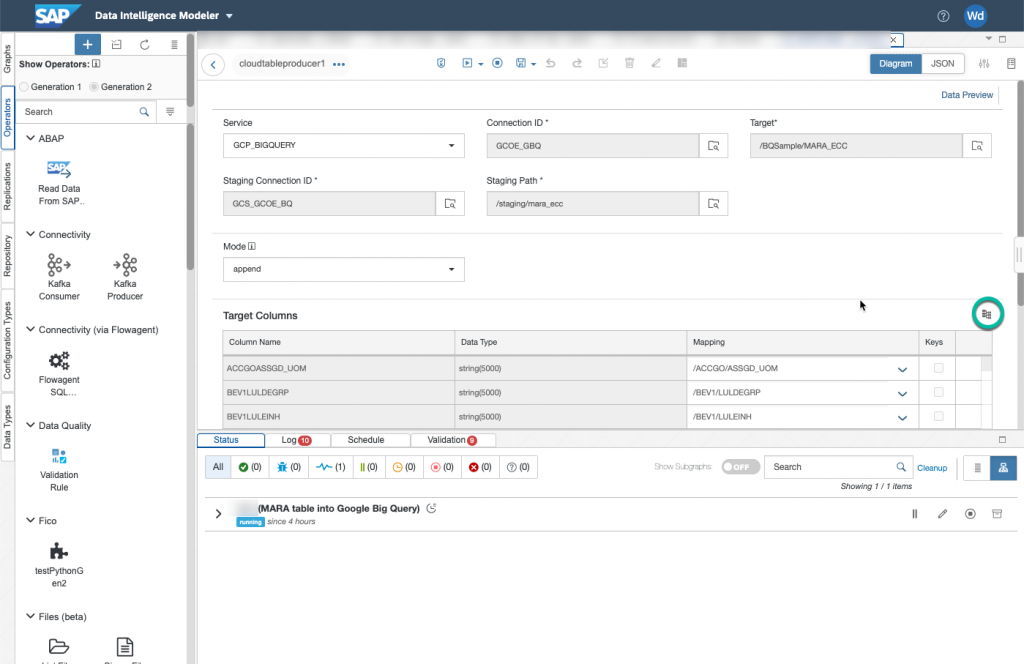
In the target columns, you can perform an autocompletion of the mapping by clicking on the button indicated below. For fields that have different names, you have to do the mapping by hand.
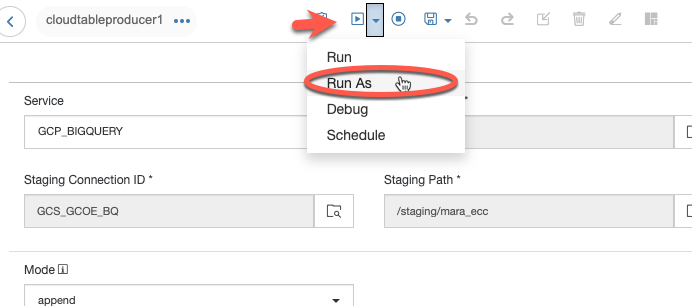
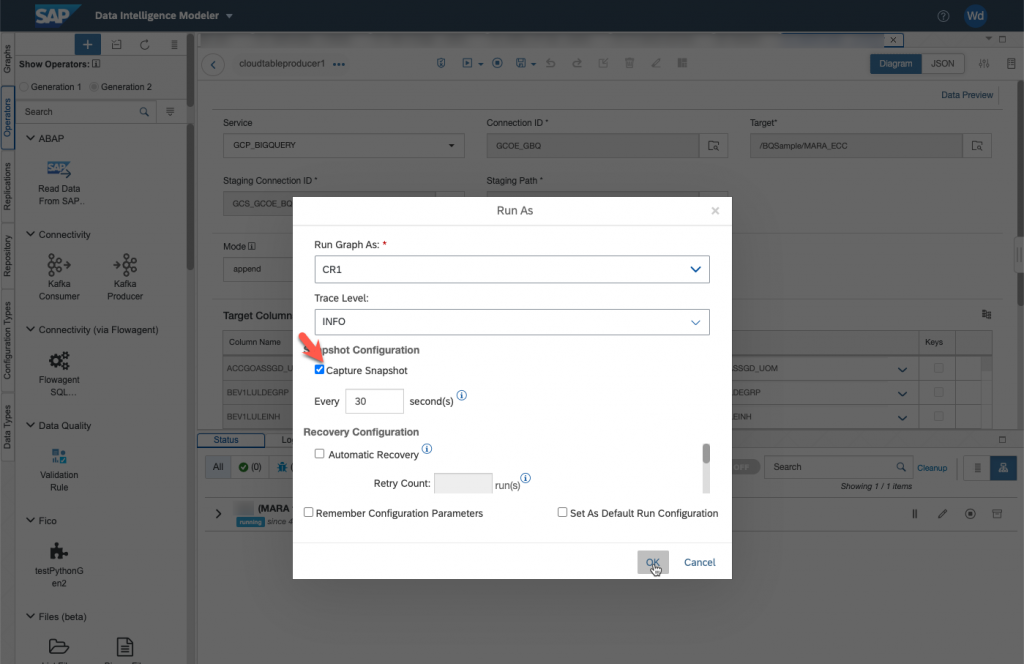
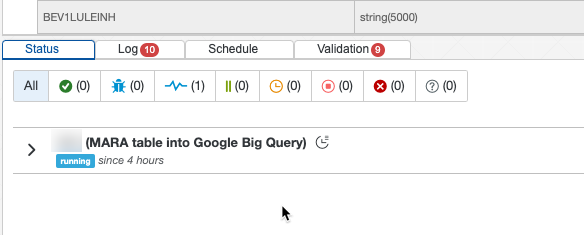
Your pipeline should be up and running in a minute or so.
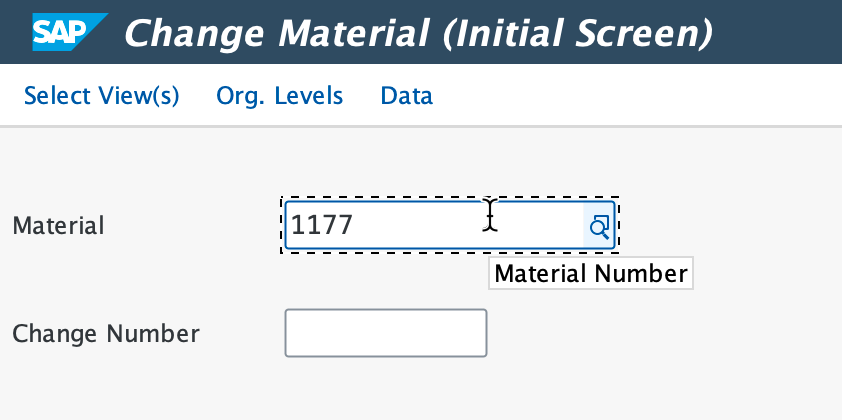
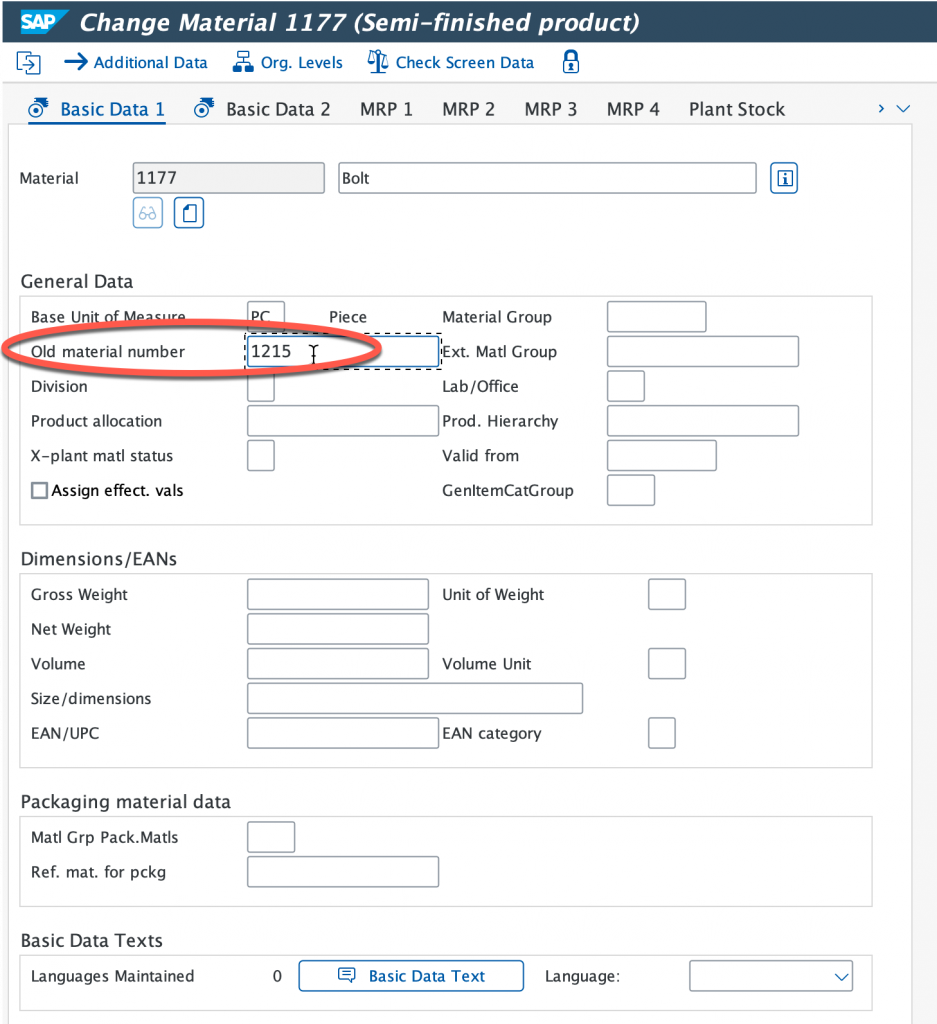
Select both Basic Data 1 & 2 and continue, now we’re going to modify the old material number.
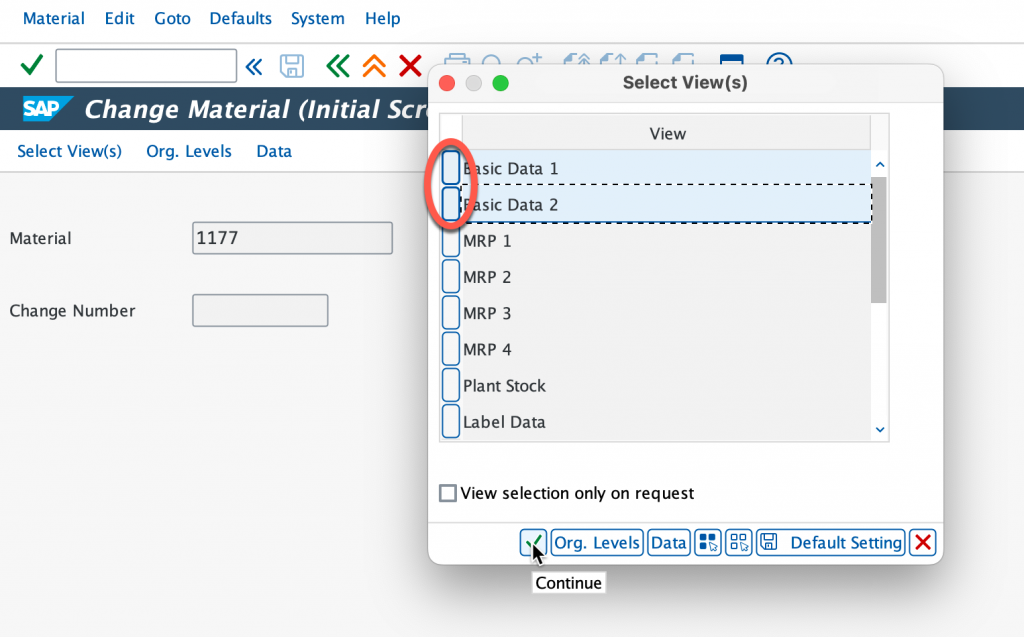
Let’s modify the old material number.
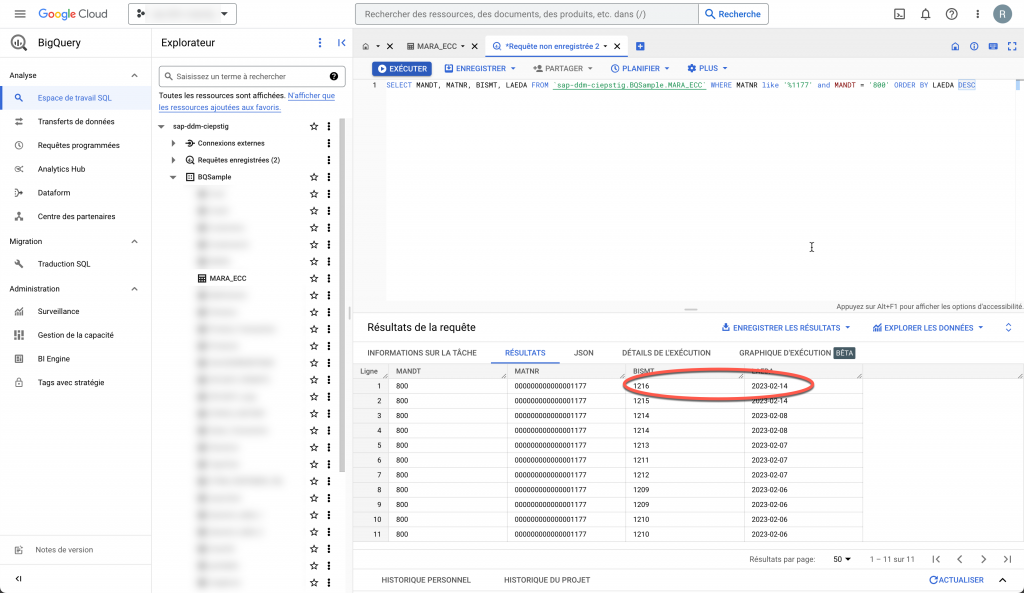
As you can see, this was very easy to set up. Once again, I have done this with a ECC system but this could also be done with an S4/HANA system just as easily.
I hope this blog was useful to you. Don’t hesitate to drop a message if you have a question.